Доступность системы. Управление доступностью ит-услуг
Идея написания этой статьи пришла после общения с одним из крупных заказчиков - коллега поведал историю выбора для своей компании провайдера облачных услуг IaaS.
Первый набор критериев для оценки сервис-провайдера выглядел примерно так: известное имя (бренд), положительная бизнес-история в области облачных услуг, адекватная стоимость. По результатам анализа возможных претендентов выбирали между несколькими компаниями, которые по вышеуказанным критериям были практически одинаковы и каждый старался доказать свои преимущества, ссылаясь на различные характеристики своих облачных услуг.
Владимир Курилов, компания «Онланта».
Так разговор дошёл до показателей надёжности. И вёлся он вокруг сравнения уровней доступности ЦОДов, в которых располагались облака. Достаточно быстро выяснилось, что только двое кандидатов располагают ЦОДами с уровнем доступности 99,98%. Выбор был сделан в пользу зарубежного провайдера облачных услуг - победила цена. Коллега объяснил всё просто, - «Какой смысл платить больше за те же самые показатели надёжности?»
Учитывая существование различных вариантов, давайте определимся с трактованием термина «Доступность» в рамках данной статьи. Определим доступность как время работоспособности системы в определённом интервале времени, выраженное в процентах к этому интервалу. Или в классическом виде: «Свойство объекта выполнять требуемую функцию при заданных условиях в течение заданного интервала времени». Что, в общем, ближе к уже достаточно устоявшемуся понятию «Готовность» системы.
Последовавший за этим решением год эксплуатации, показал, что у провайдера имеют место небольшие сбои в работе инженерных систем ЦОДа, при плановых переключениях. При этом доступность ЦОД оставалась в пределах SLA, так как переключение занимало секунды. Однако, если информационная система заказчика не останавливалась заранее перед такими переключениям, то база данных при сбоях требовала восстановления из резервной копии, что останавливало работу сотрудников на несколько часов. Выключение/включение систем, перед переключениями, немного поправляло ситуацию, но и при этом имел место простой сотрудников 25-30 минут, что тоже вызывало нарекания пользователей.
Прошёл год и теперь Коллега арендует мощности в другом облаке, где доступность одного из ЦОДов ниже вышеприведённой, а время простоев существенно уменьшилось. Как можно этого добиться и что важно при оценке надёжности работы облачных решений, а что не очень важно? Какие есть возможности экономии, снижения рисков переплаты «за красивые цифры», а не за фактическую надёжность? Как выделить критичные параметры облачных сервисов для надёжности работы Вашего приложения?
Ответы на эти вопросы я и попробую сформулировать далее.
Надёжность приложения - из чего она складывается в облаке
Надёжность сервиса приложения
Если попробовать сформулировать определение надёжности работы приложения, то оно будет звучать так: «Надёжность - это свойство приложения сохранять во времени работоспособность со всей функциональностью в него заложенной».
От чего зависит работоспособность приложения и, как надёжность приложения связана с доступностью ЦОДа?
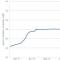
Приложение базируется на программной платформе, которая, в свою очередь, располагается на инфраструктурной платформе, использующая инженерную платформу, см. Рис. В совокупности представленные четыре уровня обеспечивают предоставление «Сервиса Приложения».

Рис. Упрощённый пример расчёта доступности Сервиса Приложения
Как видно из рисунка мы имеем дело с системой последовательных элементов, где отказ любого элемента приводит к отказу системы в целом.
Доступность такой системы (As) определяется как произведение показателей доступности всех элементов:
A i – доступность каждого последовательно соединённого компонента.
A s = 0,99995 0,99995 0,993 0998 ≈ 0,99091 или 99,091
Как видим, доступность Сервиса Приложения имеет значение, далёкое от доступности инженерной платформы ЦОДа. Можно пересчитать цифры доступности в значения простоя системы. Получается, несмотря на допустимый годовой простой инженерной платформы, в 1 час. 45 мин., для сервиса приложения годовой простой составит 86 ч. 22 мин.
Соответственно, высокий показатель доступности ЦОДа, не говорит о столь же высокой надёжности сервисов приложений, работающих в этом ЦОДе.
Надёжность сетевого приложения
Следовательно, при выборе сервис-провайдеров правильно было бы ориентироваться на совокупную доступность сервисов приложений? К сожалению, тут не всё так просто.
Оказывается, разработчик ПО способен влиять на обеспечение надёжности (устойчивости к сбоям, нагрузкам) отдельно взятого приложения. Например, надёжность работы приложения в облаке может быть значительна улучшена за счёт применения специализированных библиотек, ориентированных на обработку задержек выполняемых запросов. Приложения же написанные стандартными способами, будут обладать сравнительно более низкими показателями надёжности.
Один из вариантов реализации применения специализированных библиотек компанией Microsoft - Transient Fault Handling Application Block (см. http://msdn.microsoft.com/en-us/library/hh680934(v=pandp.50).aspx).
Надёжность программной платформы
Надёжность программной платформы, включающей операционную систему, драйверы, библиотеки, опять же, остаётся «на стороне разработчиков» и, пока, не сильно зависит от сервис-провайдера. Однако, если сервис-провайдер продумал политику правильной технической поддержки, то это может косвенно влиять на доступность.
Я говорю о «гигиенических» средствах безопасности. В первую очередь, о сервисе обновления системного программного обеспечения. Он должен быть в портфеле услуг сервис-провайдера, а ещё лучше - учтён в цене услуги «по умолчанию». Во вторую очередь, это сервис антивирусной защиты с возможностью выбора антивирусных программ. И, в третьих, резервное копирование виртуальных серверов заказчика. Это не всё, но самые важные способы, позволяющие повысить доступность вашего Сервиса Приложения.
Надёжность инфраструктурной платформы
Эта составляющая надёжности полностью зависит от сервис-провайдера и должна оцениваться Вами наравне с доступностью инженерной платформы ЦОДа. Необходимо запросить этот параметр у провайдера, поскольку как правило он не указывается в маркетинговых материалах. При этом необходимо получить разъяснения - как этот параметр рассчитывался.
Хотя надо иметь в виду, что такие данные не все сервис-провайдеры захотят представить, поскольку из расчёта становится понятна структурная схема инфраструктурного решения и используемое оборудование - а это определённое ноу-хау.
Тем не менее:
- Попросите схему функциональной структуры инфраструктурной платформы для размещения именно Вашего Сервиса приложения. Она должна включать:
- Сетевую инфраструктуры;
- Сеть хранения данных;
- Вычислительную инфраструктуру.
- Попросите указать в этой схеме места резервирования оборудования. Указывать тип используемого оборудования нет необходимости.
- Попросите указать доступность (или готовность) для каждого уровня.
- Посчитайте доступность как произведение доступностей элементов инфраструктурной платформы.
Теперь у Вас есть возможность максимально достоверно определить доступность Вашего сервиса приложения. 90% СП в России, исходя из нашего опыта, имеют суммарную доступность не выше 99%. А это риск простоев до 87 часов в год. Это нормальные показатели доступности, если у Вас нет критических для бизнеса приложений, часовой простой которых приносит Вам миллионные убытки. А если часовая остановка сродни катастрофе для Вашего бизнеса, то для Вас есть оставшиеся 10%, СП, предоставляющие сервис корпоративного уровня с доступностью Сервиса приложения на уровне 99,99%. О том, какими способами это достигается в следующем разделе.
Решения, обеспечивающие высокую доступность сервиса приложения
Заказчику в итоге неважно как соблюдается SLA по инженерным системам, ему важно какова доступность сервиса его приложений, т.е. - гарантированное время восстановления работоспособности приложения.
Системы, которые мы ранее обсуждали, имели последовательную структуру. Доступность, которую мы посчитали выше как произведение отдельных элементов - это технический предел, обеспечиваемый подобными системами. На деле в силу появления различных дополнительных факторов доступность ещё ниже. Помните вначале статьи рассказ про секундное отключение электричества и пять часов простоя?
Есть ли возможность повысить доступность приложения, если параметры доступности конкретного ЦОДа заданы и изменить их нельзя?
Ответ - можно.
Вот, например, два подхода, которые позволяют это сделать:
- Географически распределённый кластер высокой доступности;
- Восстановление обработки в географически удалённом резервном центре обработки данных (Disaster recovery).

Рис. Структурная схема географически распределённого кластера высокой доступности

Рис. Структурная схема для восстановления обработки в географически удалённом резервном центре обработки данных
Первый подход идеален, с точки зрения доступности (восстановление работоспособности происходит за секунды), но проигрывает по цене и достаточно сложен в реализации. Второй подход осуществляет восстановление сервиса из рабочей копии - это не так оперативно и небольшую часть данных при сбое придётся восстанавливать вручную, но такой вариант имеет более низкую стоимость и проще в реализации.
В обоих случаях необходимо говорить о географической удалённости ЦОДов, чтобы максимально избежать возможности взаимосвязанных ресурсов. Например, использования одних и тех же подстанций, обеспечивающих электропитание ЦОДов. Можно вспомнить отключение электричества на юго-востоке г. Москва в мае 2008 года из-за пожара на Чагинской подстанции, New York 2003 год. Поэтому резервный ЦОД должен располагаться подальше от основного.
Подход с двумя ЦОДами позволяет говорить о создании системы с параллельными элементами. При этом, с одной стороны, основной и резервный ЦОДы, являются самостоятельными системами, с другой стороны являются общей платформой для сервиса приложения - неважно в каком ЦОДе в данный момент работает приложение, оно может перемещаться из одного ЦОДа в другой.
Принципиальное отличие параллельной системы в том, что надёжность растёт с увеличением параллельных элементов системы. Расчёт доступности системы, состоящей из параллельных элементов, можно производить по формуле:

Где: A s – Суммарная доступность, доступность всей системы,
A i – доступность каждого параллельно соединённого компонента.
Для примера, рассчитаем систему географически распределённого кластера высокой доступности из двух ЦОДов с доступностью = 99%, каждый.
A s = 1-(1-0,99)*(1-0,99)= 0,9999 или 99,99
Т.е., два не самых надёжных ЦОДа могут обеспечить доступность на уровне mission-critical систем.
Определить доступность сервиса приложения в варианте восстановления обработки в географически удалённом резервном центре обработки данных с 15 минутным интервалом синхронизации для случая единичного сбоя рассчитывается так: надо запросить время восстановления сервиса приложения, гарантируемое СП; далее считаем процент от годового интервала - и результат вычитаем из единицы. Получаем доступность после первого сбоя. Например, для системы с 15 минутным интервалом синхронизации:
Общее количество часов в году 365*24=8760
Гарантированное время простоя = Время максимального простоя
15 минут или 0,25 часа, что составляет ≈ 0,003 от годового времени
Т.е. каждый сбой будет иметь вес в 0,003%. Таким образом, система до сбоя система имеет доступность, равную 100%, после первого сбоя, 99,997%, после второго сбоя 99,994%. Посчитаем тоже самое для системы с часовым интервалом синхронизации:
Гарантированное время восстановления = Время максимального простоя = 1 час, что составляет ≈ 0,01 от годового времени
Каждый сбой будет иметь вес в 0,01%. Таким образом, система до сбоя система имеет доступность, равную 100%, после первого сбоя, 99,99%, после второго сбоя 99,98%. Дальше, приверженцы теории вероятности могут поупражняться в оценке вероятности наступления первого, второго, третьего сбоев. Результат убедит, что влияние этого фактора ничтожно мало на получаемые результаты. Это позволяет мне рекомендовать предложенную методику для оценки доступности сервисов для Ваших приложений в облаке .
Резюмируя вышесказанное...
- Начните с оценки бизнес-критичности приложения, планируемого к размещению в облаке. Оцените стоимость простоя приложения. Сколько Вам будет обходиться отсутствие сервиса приложения?
- Отсюда оцените допустимое значение простоя в день, в год. Посчитайте критическую доступность сервиса приложения.
- Сопоставьте возможные потери от простоя с ценами СП, которые предлагают приемлемую для ваших приложений доступность.
- При выборе СП, отдавайте предпочтение тому, кто может обеспечить не только текущий уровень доступности, но и как дополнительный сервис/услугу предоставить улучшение доступности. Особенно если Ваш бизнес растёт и развивается.
- И оставайтесь практиками. Берите то, что дают пощупать = потестировать. Теория без практики, не очень полезна для бизнеса.
Соглашение об уровне сервиса – документ, описывающий уровень оказания услуг, ожидаемый клиентом от поставщика, основанный на показателях, применимых к данному сервису, и устанавливающий ответственность поставщика, если согласованные показатели не достигаются.
Грубо говоря, если у вас отключают интернет дома, то в конце концов вы плюнете и пойдете на прогулку, в кино или кабак, в лучшем случае надеясь на перерасчет.
Если же у вас отключается связь в офисе, то у вас останавливаются продажи (клиенты не могут дозвониться и, не дождавшись ответа по почте, уходят к другим поставщикам), бухгалтерия не может проводить платежи (здесь вы подводите уже ваших партнеров), а если вы, скажем, трейдерское бюро, то сумма убытков может достигать тысяч долларов (вы не сможете вовремя купить или сбыть акции).
Здесь может быть лирическое отступление про резервирование каналов и т.д., но у нас перед глазами есть пример – здание комплекса Москва-Сити, в котором пару лет назад неожиданным образом и основной, и резервный канал оказались от одного провайдера. А беда, как известно, не приходит одна. В итоге дважды на 7-8 часов (в рабочее время) оказывались без связи компании из рейтинга «Fortune 500».
Поэтому особо дотошные юридические службы компаний, чей бизнес особо чувствителен к качеству связи, стараются исчислять размер ущерба компании не только стоимостью не потреблённых сервисов, но и выгодой, упущенной клиентом вследствие простоя связи.
Отправные точки
Вот некоторые показатели, в том или ином составе встречающиеся в операторских документах:
ASR (Answer Seizure Ratio)
- параметр, определяющий качество телефонного соединения в заданном направлении. ASR рассчитывается как процентное отношение числа установленных в результате вызовов телефонных соединений к общему количеству совершенных вызовов в заданном направлении.
PDD (Post Dial Delay)
- параметр, определяющий период времени (в секундах), прошедший с момента вызова до момента установления телефонного соединения.
Коэффициент доступности Услуги
- отношение времени перерыва в предоставлении услуг к общему времени, когда услуга должна предоставляться.
Коэффициент потери пакетов информации
- отношение правильно принятых пакетов данных к общему количеству пакетов, которые были переданы по сети за определенный промежуток времени.
Временные задержки при передаче пакетов информации
- промежуток времени, необходимого для передачи пакета информации между двумя сетевыми устройствами.
Достоверность передачи информации
- отношение количества ошибочно переданных пакетов данных к общему числу переданных пакетов данных.
Периоды проведения работ, время оповещения абонентов и время восстановления сервисов.
Иными словами, доступность услуги 99,99% говорит о том, что оператор гарантирует не более 4,3 минут простоя связи в месяц, 99,9% - что услуга может не оказываться 43,2 минуты, а 99% - что перерыв может длиться более 7 часов. В некоторых практиках встречается разграничение доступности сети и предполагается меньшее значение параметра – в нерабочее время. На разные типы услуг (классы трафика) также предусмотрены разные значения показателей. Например, для голоса важнее всего показатель задержки – он должен быть минимальным. А скорость для него нужна невысокая, плюс часть пакетов можно терять без потери качества (примерно до 1% в зависимости от кодека). Для передачи данных на первое место выходит скорость, и потери пакетов должны стремиться к нулю.
Мировые стандарты
В западной практике принято приводить официальный отчет о параметрах сети за последний год. Вот, например, показатели для интернет-канала за май нескольких небезызвестных брендов.
Задержка передачи сигнала (Latency, ms)
| Sprintnet | Verizon | Cable&Wireless | NTT | |||||
| Факт | Стандарт | Факт | Стандарт | Факт | Стандарт | Факт | Стандарт | |
| Европа | 18.9 | 45 | 15.178 | 30 | 17.6 | 35.0 | 24.00 | 35 |
| США | 36.91 | 55 | 42.851 | 45 | 45.9 | 65.0 | 45.83 | 60 |
| Азия | 83.78 | 105 | 100.640 | 125 | 48.3 | 90.0 | 47.34 | 95 |
| Европа-Азия | 207.63 | 270 | - | - | 174.1 | 310.0 | 260.23 | 300 |
| Европа-США | 74.53 | 95 | 78.784 | 90 | 78.7 | 90.0 | 71.57 | 90 |
| Sprintnet | Verizon | Cable&Wireless | NTT | |||||
| Факт | Стандарт | Факт | Стандарт | Факт | Стандарт | Факт | Стандарт | |
| Европа | 0 | 0.3% | 0.025% | 0.5% | 0 | 0.2% | 0 | 0.3% |
| США | 0.01% | 0.3% | 0.019% | 0.5% | 0.1% | 0.2% | 0 | 0.3% |
| Азия | 0 | 0.3% | 0.004% | 1% | 0 | 0.2% | 0 | 0.3% |
| Европа-Азия | 0 | 0.3% | - | - | 0 | 0.2% | 0 | 0.3% |
| Европа-США | 0 | 0.3% | 0 | 0.5% | 0.1% | 0.2% | 0 | 0.3% |
| Sprintnet | Verizon | Cable&Wireless | NTT | |||||
| Факт | Стандарт | Факт | Стандарт | Факт | Стандарт | Факт | Стандарт | |
| Европа | 0.0017 | 2 | 0.026 | 1 | - | - | 0 | 0.5 |
| США | 0.0007 | 2 | 0.058 | 1 | - | - | 0 | 0.5 |
| Азия | 0.0201 | 2 | - | - | - | - | 0 | 0.5 |
| Европа-Азия | 0.0001 | 2 | - | - | - | - | 0 | 0.5 |
| Европа-США | 0.0001 | 2 | - | - | - | - | 0 | 0.5 |
Sprint подходит к себе более жестко, и если SLA не соблюдается (по крайней мере в отношении ), то клиенту возвращается абонентская плата за весь месяц, в котором была зафиксирована проблема.
В случае недоступности сервиса по вине NTT, оператор устанавливает для себя рамки для выявления и решения проблемы в 15 минут – по истечению которых клиенту возмещают от 1/30 до 7/30 от ежемесячного платежа. Если SLA не соответствует скорость задержки сигнала, клиент может рассчитывать на возврат суточного платежа единоразово.
Наши реалии
В Российском бизнесе трепетно к SLA относятся преимущественно международные бренды. В то же время для столичных клиентов само словосочетание тоже стало знакомым, и даже средние компании порой интересуются этим документом. Здесь хочется отметить, что соглашение об уровне сервиса не заменяет и не отменяет стандартные пункты об ответственности оператора в договоре оказания услуг, а также нормы, установленные законодательством, и подзаконные акты (например, ФЗ «О Связи», Приказ №92 «Об утверждении Норм на электрические параметры основных цифровых каналов и трактов магистральной и внутризоновых первичных сетей ВСС России» и т.д.), которым мы все свято следуем.
В практике Гарс Телеком, в случае возникновения каких-либо «факапов», споры урегулируются в рамках процедуры обработки трабл-тикетов и времени восстановления сервисов. Аварии, повлекшие неработоспособность услуги, должны ликвидироваться от 4 до 72 часов (в зависимости от причины). В случае превышения заданных параметров – абоненту компенсируется каждый дополнительный час простоя, а при достижении оператором пороговых значений – процент компенсации увеличивается.
Из интересных кейсов можно вспомнить магазин музыкальных инструментов, который обвинял нас (оператора) в падении продаж пианино (какое-то время не работал телефон). Тут опять же можно сравнивать с продвинутым клиентоориентированным западом, но лучше обратиться к российской глубинке, где не то что об SLA – вообще понятия «время восстановления сервисов» не существует. В лучшем случае – время реакции – 48 часов. За примерами даже не нужно далеко ходить – 15 км от Санкт-Петербурга – и местный оператор отнекивается от какой-либо ответственности. Говорить за всех региональных операторов было бы некрасиво, но, к сожалению, это скорее правило, чем исключение.
Какие выводы нужно сделать из этих историй
- После драки кулаками не машут – если для бизнеса есть какие-то критичные параметры, нужно подумать какие и оговорить их с оператором на этапе согласования документов
- Показатель, над которым стоит постоянно работать – это время восстановления сервисов и уровень технической поддержки. Потому что когда вообще ничего не работает – это хуже, чем когда работает, но плохо (в этом случае клиент может, по крайней мере, оперативно и безболезненно сменить оператора)
- Позаботиться о резервировании тоже стоит заранее, причем услуга должна быть от независимых операторов, хотя бы один из которых должен быть фиксированным.
Доступность ИТ-услуг имеет большое значение. Когда услуги, необходимые заказчику, недоступны, он будет недоволен. Почему заказчик должен платить за услугу, которой в реальности нет тогда, когда он в ней нуждается? Именно поэтому согласованный показатель доступности услуг часто входит в KPI.
Сотрудники ИТ-службы прикладывают много усилий, чтобы убедиться, что обозначенная цель достигнута и показать в отчетах заказчикам цифры, подтверждающие это. Обычно ИТ-компании используют для этого проценты, например, 99,999%. К сожалению, зачастую это означает, что они сосредотачиваются только на процентном измерении и упускают из виду свою истинную цель - приносить пользу заказчику.
Проблема с процентной доступностью
В основе одного из простейших способов расчета доступности лежат две части. Вы согласуете временные интервалы, в течение которых услуга должна быть доступна в отчетном периоде. Это — согласованное время обслуживания (AST). Вы измеряете время простоя (DT) в течение этого периода. Вычитаете время простоя от согласованного срока доступности сервиса и превращаете это в процент.
Если AST составляет 100 часов и время простоя 2 часа, доступность будет такой:

Проблема в том, что, хотя этот расчет достаточно прост, как и сбор данных для него, на самом деле до конца не ясно, какой именно показатель отражает полученная вами в результате расчета цифра. Я расскажу об этом немного позже.
Хуже того, с точки зрения заказчика, вы можете сообщить, что достигли согласованных целей, оставив его при этом полностью неудовлетворенным.
Отчет о значимой доступности должен основываться на измерениях, которые описывают вещи, интересующие заказчика, например, возможность отправлять и получать электронные письма или снимать наличные в банкоматах, а общий процентный показатель, по всей видимости, этого не может.
Определение целевых показателей доступности
Если вы хотите измерять, документировать и отчитываться о доступности таким образом, чтобы это было полезно для вашей организации и ваших заказчиков, вам нужно сделать две вещи. Во-первых, определить контекст и закрепить смысл понятия "доступность" для вас и ваших заказчиков. Для этого вам нужно поговорить с ними.
Во-вторых, вам следует тщательно продумать ряд практических вопросов: что вы будете измерять, как вы будете собирать данные, как будете их документировать и сообщать о полученных результатах.
Общение с заказчиками
Прежде, чем предпринимать какие-либо действия, необходимо выяснить, что именно важно для ваших заказчиков, и какое влияние на них оказывает потеря доступности. Это позволит вам поставить реалистичные цели, которые учитывают технологические, бюджетные и кадровые ограничения.
Но что именно сказать заказчикам? Отличной отправной точкой для разговора может стать влияние времени простоя. Ниже приведены пять вопросов, которые вы должны задать:
- Какие бизнес-функции являются критически значимыми и имеют важнейший приоритет в защите от простоя?
- Как время простоя влияет на бизнес?
- Как частота простоя влияет на бизнес?
- Какое влияние простои оказывают на производительность организации?
- Как эти вынужденные простои воспринимают заказчики организации?
Критически значимые бизнес-функции
Большинство ИТ-услуг поддерживают несколько бизнес-процессов, некоторые из которых являются критическими, а другие менее важны. Например, банкомат может поддерживать выдачу наличных и печать чеков. Способность распределять наличные деньги имеет решающее значение, в то время как неспособность напечатать чек оказывает гораздо меньшее влияние.
Вам нужно поговорить с заказчиками и определить степень важности различных функций для бизнеса. Вы можете составить таблицу, в которой отметить последствия для бизнеса, которые несёт простой каждой из этих функций. Пример:
Таблица 1 - Важность услуг в процентном соотношении
NB : Цифры не должны в сумме давать 100%
Из этой таблицы видно, что данная услуга вообще не имеет значения, если нет возможности отправлять и получать электронные письма, и её ценность уменьшается до половины нормального уровня, если общедоступные папки не могут быть прочитаны. Это говорит ИТ-службе, что нужно сосредоточиться на качестве работы почтовой службы.
Продолжительность и частота простоя
Вам нужно выяснить, как на бизнес заказчика влияет частота и продолжительность простоя.
Я уже упоминал, что процентная доступность может быть недостаточной. Когда услуга, которая должна быть доступна в течение 100 часов, имеет 98% доступность, это показывает, что было два часа простоя. Но это может означать как один двухчасовой, так и несколько более коротких инцидентов. Относительное влияние одного длительного инцидента или ряда коротких инцидентов будет различным, в зависимости от характера бизнеса и бизнес-процессов.
Например, биллинг, который длится два дня и должен быть перезапущен после любого сбоя, будет серьезно затронут каждым коротким отключением, но один вынужденный простой, который длится долгое время, может иметь гораздо меньшее значение. С другой стороны, одноминутное отключение может никак не повлиять на работу Интернет-магазина, но уже через два часа это может привести к значительной потере клиентов. Как только вы будете иметь представление о вероятном влиянии простоя на бизнес, вы сможете создать гораздо более эффективную инфраструктуру, приложения и процессы, которые действительно помогут заказчику.
Вот пример того, как можно измерить и документировать доступность, чтобы отразить тот факт, что влияние времени простоя варьируется:
Таблица 2 - Длительность отключения и максимальная частота
Если вы используете такую таблицу, когда обсуждаете частоту и продолжительность простоя с заказчиками, эти цифры, вероятно, будут намного полезнее, чем процентная доступность, и они, безусловно, будут иметь бОльшее значение для ваших заказчиков.
Время простоя и производительность
Я упоминал, что процентная доступность не очень полезна для общения с заказчиками о частоте и продолжительности простоя. С другой стороны, когда вы обсуждаете влияние простоя на производительность, процентное взаимоотношение может очень пригодиться.
Большинство инцидентов не вызывают полной потери обслуживания для всех пользователей. Некоторые пользователи могут быть не затронуты, в то время как другие полностью отключены. Может быть, есть всего один пользователь с неисправным ПК, который не может получить доступ к каким-либо услугам. Вы даже можете классифицировать это как потерю обслуживания на 100%, но это будет совершенно недостижимая цель для ИТ и не может являться справедливым критерием доступности.
С другой стороны, вы можете сказать, что услуга доступна, пока кто-то все еще может получить к ней доступ. Тем не менее, не нужно много воображения, чтобы понять, как будут чувствовать себя заказчики, если услуга будет значиться, как доступная, в то время как многие люди просто не могут ею воспользоваться.
Одним из способов определения воздействия является вычисление процента потерянных пользовательских минут. Чтобы сделать это:
- Вычислите PotentialUserMinutes. Это общее количество пользователей, которые работают в единицу времени. Например, если у вас 10 сотрудников, которые работают в течение 8 часов, то PotentialUserMinutes — это 10 x 8 x 60 = 4800
- Вычислите UserOutageMinutes. Это общее количество пользователей, которые не могли работать, умноженные на время, когда они не смогли работать. Например, если инцидент помешал 5 сотрудникам работать в течение 10 минут, то UserOutageMinutes — 50.
- Рассчитайте процентную доступность, используя очень похожую формулу на ту, что мы видели ранее
В приведенном примере, мы получили следующую доступность:

Вы можете использовать эту же методику для расчета влияния потерянной доступности IP-телефонии в колл-центре с точки зрения PotentialAgentPhoneMinutes и LostAgentPhoneMinutes; в случае приложений, которые занимаются транзакциями или производством, вы можете использовать аналогичный подход для количественной оценки воздействия инцидента на бизнес. Вы сравниваете количество транзакций, которые ожидались бы без простоя, по отношению к количеству фактических транзакций или объема производства, который предполагался по отношению к фактическому.
Измерение доступности и отчётность
После того, как вы согласовали и задокументировали целевые показатели доступности, нужно подумать о практических аспектах того, как вы можете измерять и сообщать о доступности. Например:
- Что вы будете измерять?
- Как вы будете собирать данные?
- Как вы будете документировать свои выводы и сообщать о них?
Что измер
я
ть
Очень важно измерять доступность и отчитываться о ней в тех же терминах, которыми определены согласованные с заказчиками целевые показатели, и которые основаны на общем понимании того, что на самом деле является доступностью для заказчика. Цели должны иметь для него смысл и гарантировать, что усилия ИТ-службы сосредоточены на предоставлении поддержки его бизнесу.
Как правило, эти цели являются частью соглашения об уровне услуг (SLA) между ИТ и заказчиком, но нужно быть осторожным, чтобы цифры из SLA не стали вашей целью. Ваша реальная цель — предоставлять услуги, отвечающие ожиданиям ваших заказчиков.
Как собирать данные
Существует много различных путей сбора данных о доступности ИТ-услуг. Некоторые из них просты, но не слишком точны, некоторые достаточно дороги. Вы можете использовать только один подход, или комбинировать несколько из них для создания своих отчетов.
Сбор данных в технической поддержке
Один из способов сбора данных о доступности — через службу поддержки. Обычно сотрудники службы определяют влияние и продолжительность каждого инцидента на бизнес, поскольку это - часть управления инцидентами. Эти данные вполне можно использовать для определения продолжительности инцидентов и количества затронутых пользователей.
Данный подход, как правило, довольно недорогой. Однако может привести к спорам о точности данных о доступности.
Измерение доступности инфраструктуры и приложений
Этот подход включает в себя инструментарий для всех компонентов, необходимых для обеспечения услуги, и расчета доступности на основе понимания того, какой вклад вносит каждый компонент.
Он может быть очень эффективным, но может пропустить небольшие сбои. Например, незначительное повреждение базы данных может привести к тому, что некоторые пользователи не смогут осуществлять определенные типы транзакций. Этот метод также может упустить влияние общих компонентов, например, у одного из моих клиентов регулярно не работала электронная почта из-за ненадежных серверов DHCP в их штаб-квартире, но ИТ-служба не зарегистрировала это как время простоя электронной почты.
Фиктивные заказчики
Некоторые компанию используют фиктивных заказчиков для отправки известных транзакций из определенных точек в сети, чтобы проверить доступность.
Фактически — это измерение сквозной доступности. В зависимости от размера и сложности сети, внедрение этого подхода может быть достаточно дорогостоящим, к тому же он сообщает только о доступности от конкретных фиктивных заказчиков. Это значит, что небольшие сбои могут быть пропущены, например, если инцидент привел к некорректной работе определенного веб-браузера, тогда как фиктивный заказчик использует другой браузер.
Инструменты, которые поддерживают такой сбор данных, также часто сообщают об эффективности обслуживания и доступности, что может быть полезным дополнением.
Доработка приложений
Некоторые компании добавляют в свои приложения специальный код, чтобы следить за сквозной доступностью. Это поможет реально измерить сквозную доступность услуг при условии, что эта задача ставилась на момент разработки приложения. Как правило, эта доработка включает код как в клиентском приложении, так в серверной части.
Если она будет реализована хорошо, то сможет не только собирать данные о доступности, но и поможет точно определить, где именно произошел сбой, что поможет повысить доступность за счет сокращения времени, необходимого на решение инцидентов.
Как документировать и сообщать о своих выводах
Когда вы собрали данные о доступности, вам необходимо подумать о том, как сообщить о результатах своим заказчикам.
Планируйте время простоя
Один аспект измерения доступности и отчетности, который часто упускается из виду, — это время простоя. Если вы не будете учитывать планируемое время простоя при разработке отчетов о доступности, вы рискуете включить в них показатели, которые не соответствуют действительности.
Существует несколько способов убедиться, что запланированное время простоя не приводит к раздуванию статистики. Один из них — иметь запланированное время простоя в течение определенного отрезка времени, который не включается в расчет доступности. Другой — назначить запланированное время простоя. Например, некоторые организации могут не учитывать время простоя, запланированное на будущее, на месяц вперед.
Независимо от того, что вы решите сделать, важно, чтобы ваше SLA четко определяло, как будет учитываться запланированное время простоя.
Соглашение об отчетном периоде
Ранее я говорил об ограничениях, которые скрывает процентная доступность. Тем не менее, она применяется и продолжает широко использоваться. Поэтому важно понимать, что вам нужно указать период времени, в течение которого выполняются вычисления и предоставляются отчеты, так как это может иметь критическое значение для цифр, которые будут в ваших отчетах.
Например, рассмотрим ИТ-компанию, которая согласилась на услугу 24×7 и доступность 99%. Предположим, что произошел восьмичасовой перерыв:
- если мы отчитываемся о доступности еженедельно, то AST (согласованное время обслуживания) составляет 24 x 7 часов = 168 часов
- ежемесячно AST (24 x 365) / 12 = 730 часов
- ежеквартально AST (24 x 365) / 4 = 2190 часов
Ввод этих чисел в уравнение доступности дает:
- Еженедельная доступность = 100% x (168-8) / 168 = 95,2%.
- Ежемесячная доступность = 100% x (730 — 8) / 730 = 98,9%
- Квартальная доступность = 100% x (2190-8) / 2190 = 99,6%
Каждый из них является действительным показателем доступности службы, но только один из них показывает, что цель была выполнена.
В заключении
Почти каждая ИТ-компания, с которой я работал, измеряет доступность своих услуг и отчитывается о ней. Действительно эффективные ИТ-отделы работают со своими заказчиками, чтобы оптимизировать собственные вложения и обеспечить отличный уровень доступности. Но, к сожалению, многие ИТ-компании сосредоточены на числах в SLA и не удовлетворяют потребности своих заказчиков, даже если в конечном итоге показывают в отчетах согласованные цифры.
Это длинная статья, ниже перечислены ключевые моменты, которые затронуты в ней:
- Не нужно говорить заказчику, что вы предоставили 98% -ную доступность, если у вас нет понимания влияния 2-процентного времени простоя
- Поговорите со своими заказчиками и убедитесь, что вы понимаете влияние любого простоя на них и на конечных заказчиков
- Подумайте о способах защиты критических бизнес-процессов ваших заказчиков
- Найдите способы измерения частоты и продолжительности простоя, также степени влияния времени простоя на производительность, которые соответствуют потребностям ваших заказчиков
- Согласуйте, документируйте и указывайте показатели доступности способами, которые имеют смысл для ваших заказчиков и помогают планировать
- Используйте соответствующие инструменты, чтобы правильно оценить доступность и сообщить в отчете.
Что еще вы могли бы добавить к моим советам? Пожалуйста, пишите в комментариях.

Есть разновидности бизнеса, где перерывы в предоставлении сервиса недопустимы. Например, если у сотового оператора из-за поломки сервера остановится биллинговая система, абоненты останутся без связи. От осознания возможных последствий этого события возникает резонное желание подстраховаться.
Мы расскажем какие есть способы защиты от сбоев серверов и какие архитектуры используют при внедрении VMmanager Cloud: продукта, который предназначен для создания кластера высокой доступности .
Предисловие
В области защиты от сбоев на кластерах терминология в Интернете различается от сайта к сайту. Для того чтобы избежать путаницы, мы обозначим термины и определения, которые будут использоваться в этой статье.- Отказоустойчивость (Fault Tolerance, FT) - способность системы к дальнейшей работе после выхода из строя какого-либо её элемента.
- Кластер - группа серверов (вычислительных единиц), объединенных каналами связи.
- Отказоустойчивый кластер (Fault Tolerant Cluster, FTC) - кластер, отказ сервера в котором не приводит к полной неработоспособности всего кластера. Задачи вышедшей из строя машины распределяются между одной или несколькими оставшимися нодами в автоматическом режиме.
- Непрерывная доступность (Continuous Availability, CA) - пользователь может в любой момент воспользоваться сервисом, перерывов в предоставлении не происходит. Сколько времени прошло с момента отказа узла не имеет значения.
- Высокая доступность (High Availability, HA) - в случае выхода из строя узла пользователь какое-то время не будет получать услугу, однако восстановление системы произойдёт автоматически; время простоя минимизируется.
- КНД - кластер непрерывной доступности, CA-кластер.
- КВД - кластер высокой доступности, HA-кластер.
На первый взгляд самый привлекательный вариант для бизнеса тот, когда в случае сбоя обслуживание пользователей не прерывается, то есть кластер непрерывной доступности. Без КНД никак не обойтись как минимум в задачах уже упомянутого биллинга абонентов и при автоматизации непрерывных производственных процессов. Однако наряду с положительными чертами такого подхода есть и “подводные камни”. О них следующий раздел статьи.
Continuous availability / непрерывная доступность
Бесперебойное обслуживание клиента возможно только в случае наличия в любой момент времени точной копии сервера (физического или виртуального), на котором запущен сервис. Если создавать копию уже после отказа оборудования, то на это потребуется время, а значит, будет перебой в предоставлении услуги. Кроме этого, после поломки невозможно будет получить содержимое оперативной памяти с проблемной машины, а значит находившаяся там информация будет потеряна.Для реализации CA существует два способа: аппаратный и программный. Расскажем о каждом из них чуть подробнее.
Аппаратный способ
представляет собой “раздвоенный” сервер: все компоненты дублированы, а вычисления выполняются одновременно и независимо. За синхронность отвечает узел, который в числе прочего сверяет результаты с половинок. В случае несоответствия выполняется поиск причины и попытка коррекции ошибки. Если ошибка не корректируется, то неисправный модуль отключается.
На Хабре недавно была на тему аппаратных CA-серверов. Описываемый в материале производитель гарантирует, что годовое время простоя не более 32 секунд. Так вот, для того чтобы добиться таких результатов, надо приобрести оборудование. Российский партнёр компании Stratus сообщил, что стоимость CA-сервера с двумя процессорами на каждый синхронизированный модуль составляет порядка $160 000 в зависимости от комплектации. Итого на кластер потребуется $1 600 000.
Программный способ.
На момент написания статьи самый популярный инструмент для развёртывания кластера непрерывной доступности - от VMware. Технология обеспечения Continuous Availability в этом продукте имеет название “Fault Tolerance”.
В отличие от аппаратного способа данный вариант имеет ограничения в использовании. Перечислим основные:
- На физическом хосте должен быть процессор:
- Intel архитектуры Sandy Bridge (или новее). Avoton не поддерживается.
- AMD Bulldozer (или новее).
- Машины, на которых используется Fault Tolerance, должны быть объединены в 10-гигабитную сеть с низкими задержками. Компания VMware настоятельно рекомендует выделенную сеть.
- Не более 4 виртуальных процессоров на ВМ.
- Не более 8 виртуальных процессоров на физический хост.
- Не более 4 виртуальных машин на физический хост.
- Невозможно использовать снэпшоты виртуальных машин.
- Невозможно использовать Storage vMotion.
Экспериментально установлено, что технология Fault Tolerance от VMware значительно “тормозит” виртуальную машину. В ходе исследования vmgu.ru после включения FT производительность ВМ при работе с базой данных упала на 47%.
Лицензирование vSphere привязано к физическим процессорам. Цена начинается с $1750 за лицензию + $550 за годовую подписку и техподдержку. Также для автоматизации управления кластером требуется приобрести VMware vCenter Server, который стоит от $8000. Поскольку для обеспечения непрерывной доступности используется схема 2N, для того чтобы работали 10 нод с виртуальными машинами, нужно дополнительно приобрести 10 дублирующих серверов и лицензии к ним. Итого стоимость программной части кластера составит 2 *(10 + 10)*(1750 + 550)+ 8000 =$100 000.
Мы не стали расписывать конкретные конфигурации нод: состав комплектующих в серверах всегда зависит от задач кластера. Сетевое оборудование описывать также смысла не имеет: во всех случаях набор будет одинаковым. Поэтому в данной статье мы решили считать только то, что точно будет различаться: стоимость лицензий.
Стоит упомянуть и о тех продуктах, разработка которых остановилась.
Есть Remus на базе Xen, бесплатное решение с открытым исходным кодом. Проект использует технологию микроснэпшотов. К сожалению, документация давно не обновлялась; например, установка описана для Ubuntu 12.10, поддержка которой прекращена в 2014 году. И как ни странно, даже Гугл не нашёл ни одной компании, применившей Remus в своей деятельности.
Предпринимались попытки доработки QEMU с целью добавить возможность создания continuous availability кластера. На момент написания статьи существует два таких проекта.
Первый - Kemari , продукт с открытым исходным кодом, которым руководит Yoshiaki Tamura. Предполагается использовать механизмы живой миграции QEMU. Однако тот факт, что последний коммит был сделан в феврале 2011 года говорит о том, что скорее всего разработка зашла в тупик и не возобновится.
Второй - Micro Checkpointing , основанный Michael Hines, тоже open source. К сожалению, уже год в репозитории нет никакой активности. Похоже, что ситуация сложилась аналогично проекту Kemari.
Таким образом, реализации continuous availability на базе виртуализации KVM в данный момент нет.
Итак, практика показывает, что несмотря на преимущества систем непрерывной доступности, есть немало трудностей при внедрении и эксплуатации таких решений. Однако существуют ситуации, когда отказоустойчивость требуется, но нет жёстких требований к непрерывности сервиса. В таких случаях можно применить кластеры высокой доступности, КВД.
High availability / высокая доступность
В контексте КВД отказоустойчивость обеспечивается за счёт автоматического определения отказа оборудования и последующего запуска сервиса на исправном узле кластера.В КВД не выполняется синхронизация запущенных на нодах процессов и не всегда выполняется синхронизация локальных дисков машин. Стало быть, использующиеся узлами носители должны быть на отдельном независимом хранилище, например, на сетевом хранилище данных. Причина очевидна: в случае отказа ноды пропадёт связь с ней, а значит, не будет возможности получить доступ к информации на её накопителе. Естественно, что СХД тоже должно быть отказоустойчивым, иначе КВД не получится по определению.
Таким образом, кластер высокой доступности делится на два подкластера:
- Вычислительный. К нему относятся ноды, на которых непосредственно запущены виртуальные машины
- Кластер хранилища. Тут находятся диски, которые используются нодами вычислительного подкластера.
- Heartbeat версии 1.х в связке с DRBD;
- Pacemaker;
- VMware vSphere;
- Proxmox VE;
- XenServer;
- Openstack;
- oVirt;
- Red Hat Enterprise Virtualization;
- Windows Server Failover Clustering в связке с серверной ролью “Hyper-V”;
- VMmanager Cloud.
VMmanager Cloud
Наше решение VMmanager Cloud использует виртуализацию QEMU-KVM. Мы сделали выбор в пользу этой технологии, поскольку она активно разрабатывается и поддерживается, а также позволяет установить любую операционную систему на виртуальную машину. В качестве инструмента для выявления отказов в кластере используется Corosync. Если выходит из строя один из серверов, VMmanager поочерёдно распределяет работавшие на нём виртуальные машины по оставшимся нодам.В упрощённой форме алгоритм такой:
- Происходит поиск узла кластера с наименьшим количеством виртуальных машин.
- Выполняется запрос хватает ли свободной оперативной памяти для размещения текущей ВМ в списке.
- Если памяти для распределяемой машины достаточно, то VMmanager отдаёт команду на создание виртуальной машины на этом узле.
- Если памяти не хватает, то выполняется поиск на серверах, которые несут на себе большее количество виртуальных машин.
Практика показывает, что лучше выделить одну или несколько нод под аварийные ситуации и не развёртывать на них ВМ в период штатной работы. Такой подход исключает ситуацию, когда на “живых” нодах в кластере не хватает ресурсов, чтобы разместить все виртуальные машины с “умершей”. В случае с одним запасным сервером схема резервирования носит название “N+1”.
VMmanager Cloud поддерживает следующие типы хранилищ: файловая система, LVM, Network LVM, iSCSI и Ceph . В контексте КВД используются последние три.
При использовании вечной лицензии стоимость программной части кластера из десяти “боевых” узлов и одного резервного составит €3520 или $3865 на сегодняшний день (лицензия стоит €320 за ноду независимо от количества процессоров на ней). В лицензию входит год бесплатных обновлений, а со второго года они будут предоставляться в рамках пакета обновлений стоимостью €880 в год за весь кластер.
Рассмотрим по каким схемам пользователи VMmanager Cloud реализовывали кластеры высокой доступности.
FirstByte
Компания FirstByte начала предоставлять облачный хостинг в феврале 2016 года. Изначально кластер работал под управлением OpenStack. Однако отсутствие доступных специалистов по этой системе (как по наличию так и по цене) побудило к поиску другого решения. К новому инструменту для управления КВД предъявлялись следующие требования:- Возможность предоставления виртуальных машин на KVM;
- Наличие интеграции с Ceph;
- Наличие интеграции с биллингом подходящим для предоставления имеющихся услуг;
- Доступная стоимость лицензий;
- Наличие поддержки производителя.
Отличительные черты кластера:
- Передача данных основана на технологии Ethernet и построена на оборудовании Cisco.
- За маршрутизацию отвечает Cisco ASR9001; в кластере используется порядка 50000 IPv6 адресов.
- Скорость линка между вычислительными нодами и коммутаторами 10 Гбит/с.
- Между коммутаторами и нодами хранилища скорость обмена данными 20 Гбит/с, используется агрегирование двух каналов по 10 Гбит/с.
- Между стойками с нодами хранилища есть отдельный 20-гигабитный линк, используемый для репликации.
- В узлах хранилища установлены SAS-диски в связке с SSD-накопителями.
- Тип хранилища - Ceph.

Данная конфигурация подходит для хостинга сайтов с высокой посещаемостью, для размещения игровых серверов и баз данных с нагрузкой от средней до высокой.
FirstVDS
Компания FirstVDS предоставляет услуги отказоустойчивого хостинга, запуск продукта состоялся в сентябре 2015 года.К использованию VMmanager Cloud компания пришла из следующих соображений:
- Большой опыт работы с продуктами ISPsystem.
- Наличие интеграции с BILLmanager по умолчанию.
- Отличное качество техподдержки продуктов.
- Поддержка Ceph.
- Передача данных основана на сети Infiniband со скоростью соединения 56 Гбит/с;
- Infiniband-сеть построена на оборудовании Mellanox;
- В узлах хранилища установлены SSD-носители;
- Используемый тип хранилища - Ceph.

В случае общего отказа Infiniband-сети связь между хранилищем дисков ВМ и вычислительными серверами выполняется через Ethernet-сеть, которая развёрнута на оборудовании Juniper. “Подхват” происходит автоматически.
Благодаря высокой скорости взаимодействия с хранилищем такой кластер подходит для размещения сайтов со сверхвысокой посещаемостью, видеохостинга с потоковым воспроизведением контента, а также для выполнения операций с большими объёмами данных.
Эпилог
Подведём итог статьи. Если каждая секунда простоя сервиса приносит значительные убытки - не обойтись без кластера непрерывной доступности.Однако если обстоятельства позволяют подождать 5 минут пока виртуальные машины разворачиваются на резервной ноде, можно взглянуть в сторону КВД. Это даст экономию в стоимости лицензий и оборудования.
Кроме этого не можем не напомнить, что единственное средство повышения отказоустойчивости - избыточность. Обеспечив резервирование серверов, не забудьте зарезервировать линии и оборудование передачи данных, каналы доступа в Интернет, электропитание. Всё что только можно зарезервировать - резервируйте. Такие меры исключают единую точку отказа, тонкое место, из-за неисправности в котором прекращает работать вся система. Приняв все вышеописанные меры, вы получите отказоустойчивый кластер, который действительно трудно вывести из строя. Добавить метки
В настоящее время развитие технологии идет нарастающими темпами. По этой причине во многих организациях необходимое для работы аппаратное и программное обеспечение становится более многочисленным и разнообразным, несмотря на все попытки его стандартизации. Старые и новые технологии вынуждены существовать вместе. Такое сосуществование приводит к появлению дополнительных сетевых средств, интерфейсов и средств коммуникации. Происходит усиление зависимости бизнеса от технологий.
Несколько часов простоя компьютера могут иметь серьезные последствия для бизнеса и репутации компании на рынке, особенно сейчас, когда Интернет превращается в электронный вариант рынка. В этом электронном мире конкурентов друг от друга отделяет простое нажатие на клавишу «мыши». В этой связи особенно важным фактором становится степень удовлетворенности заказчиков. Эта одна из причин, почему в настоящее время вычислительные системы должны быть доступны 24 часа в сутки семь дней в неделю.
14.1.1. Основные понятия
На рис. 14.1 схематично представлены базовые понятия процесса Управления Доступностью.
Рис. 14.1. Концептуальные понятия процесса Управления Доступностью (источник: OGC)
Доступность
Высокий Уровень Доступности означает, что заказчик имеет практически постоянный доступ к ИТ-сервису благодаря сокращению времени простоя и быстрому восстановлению предоставления услуг. Уровень Доступности определяется с помощью метрик. Доступность сервиса зависит от:
Сложности ИТ-инфраструктуры;
Надежности компонентов;
Способности быстро и эффективно реагировать на сбои;
Качества обслуживания и качества работы поддерживающих организаций и поставщиков;
Качества и границ компетенции процессов операционного управления.
Надежность, в контексте данного процесса, означает доступность сервиса в течение согласованного периода времени без каких-либо сбоев. Эта концепция включает в себя понятие устойчивости . Надежность сервиса будет возрастать, если предпринимать превентивные меры против возникновения простоев. Надежность сервиса является статистическим показателем и определяется сочетанием следующих факторов:
Надежность компонентов, используемых для предоставления сервиса;
Способность сервиса или его компонентов эффективно функционировать, несмотря на сбой одной или нескольких подсистем (устойчивость);
Профилактическое обслуживание для предотвращения простоев.
Понятия «обслуживание» и «способность к восстановлению» предполагают выполнение работ по обеспечению функционирования сервиса и его восстановлению после сбоев, а также проведение профилактического обслуживания и регламентных (плановых) проверок, а именно:
Принятие мер по предотвращению сбоев;
Своевременное обнаружение сбоев;
Проведение диагностики, включая автоматическую самодиагностику компонентов;
Ликвидация сбоев;
Восстановление функционирования после сбоя;
Восстановление сервиса.
Предоставление сервиса внешними поставщиками
Данное понятие относится к договорным обязательствам внешних поставщиков сервиса (подрядчики, сторонние организации). Договорами определяется поддержка, которая будет обеспечена сервисам, поставляемым внешними организациями (аутсорсинг). Поскольку это только часть ИТ-сервиса, данный термин не относится к общей доступности сервиса. Если подрядчик несет ответственность за сервис в целом, как это бывает, например, при заключении договора хозяйственного обеспечения, тогда термины «Предоставление сервиса» и «доступность» будут синонимами. Для эффективного Управления Доступностью необходимо знание бизнеса и ИТ-среды. Важно понять, что доступность нельзя просто «купить»: доступность должна закладываться на самых ранних этапах разработки и внедрения. В конечном счете доступность зависит от сложности инфраструктуры, надежности компонентов, профессионализма ИТ-организации и ее подрядчиков и от качества самого процесса.
14.2. Цели процесса
Целью Процесса Управления Доступностью является обеспечение рентабельного и согласованного Уровня Доступности ИТ-сервиса, который поможет бизнесу в достижении поставленных целей. Такое определение цели процесса означает, что потребности заказчика (бизнеса) должны соответствовать тому, что могут предложить ИТ-инфраструктура и организация. Если имеется расхождение между спросом и предложением, тогда Процесс Управления Доступностью должен предложить выход из такой ситуации. Более того, данный процесс гарантирует оценку достигнутых Уровней Доступности и их дальнейшее совершенствование в случае необходимости. Это означает, что в рамках процесса выполняются как проактивные, так и реактивные виды деятельности. При разработке процесса следует исходить из следующих предпосылок:
Использование Процесса Управления Доступностью необходимо для достижения наибольшей удовлетворенности заказчика. Доступность и надежность – два показателя, во многом определяющие восприятие предоставляемых услуг заказчиком.
Высокая степень доступности не означает отсутствие сбоев. Управление Доступностью в основном отвечает за профессиональное реагирование на такие нежелательные ситуации.
Проектирование процесса требует не только полного понимания информационных технологий, но понимания процессов и услуг заказчика. Достижение целей возможно только путем сочетания этих двух аспектов.
У Процесса Управления Доступностью широкая сфера действия, охватывающая новые и уже существующие услуги, отношения с внешними и внутренними поставщиками, все компоненты инфраструктуры (аппаратное и программное обеспечение, сети и т. д.) и влияющие на доступность организационные аспекты, такие как Уровень Знаний Персонала, управленческие процессы, процедуры и инструментальные средства.
14.2.1. Преимущества использования процесса
Основное преимущество, которое дает Процесс Управления Доступностью, состоит в том, что услуги, разработанные, внедренные и находящиеся под Управлением ИТ-организации, отвечают требованиям, предъявляемым к доступности сервиса. Полное понимание бизнес-процессов заказчика и информационных технологий в сочетании с постоянным стремлением максимально расширить доступность сервиса в разумных пределах могут во многом содействовать формированию реальной культуры сервиса. Другие преимущества данного процесса состоят в следующем:
Создание единой точки контактов по вопросам доступности продуктов и услуг и наличие одного человека, отвечающего за эти вопросы;
Гарантируется соответствие новых продуктов и услуг предъявляемым к ним требованиям и согласованному с заказчиком стандарту доступности;
Уровень Затрат поддерживается на приемлемом уровне;
Постоянный мониторинг стандартов доступности и их совершенствование по мере необходимости;
В случае недоступности сервиса выполнение восстановительных мероприятий, соответствующих ситуации;
Уменьшение количества отказов в доступе к системам и сокращение периода недоступности сервиса;
Смещение акцентов с исправления дефектов на улучшение сервиса;
Простота обоснования добавочной стоимости для ИТ-организации.
Процесс Управления Доступностью связан со следующими процессами ITIL.
Управление Уровнем Сервиса
Процесс Управления Уровнем Сервиса осуществляет согласование и Управление Соглашениями об Уровне Сервиса, в которых Доступность является одним из важнейших параметров.
Управление Конфигурациями
Процесс Управления Конфигурациями располагает информацией об инфраструктуре и может предоставлять ценную информацию Процессу Управления Доступностью.
Управление Мощностями
Изменение Мощностей часто влияет на доступность сервиса, а изменения параметров доступности затрагивают параметры мощности сервиса. Процесс Управления Мощностями располагает обширной информацией, включая информацию об инфраструктуре. Поэтому эти процессы часто обмениваются информацией о сценариях модернизации ИТ-компонентов или их вывода из операционной среды, а также о тенденциях в сфере доступности, которые могут вызвать изменения в требованиях к мощностям сервиса.
Управление Непрерывностью Сервиса
Процесс Управления Доступностью не несет ответственности за восстановление бизнес-процессов после катастрофы. Это обязанность Процесса Управления Непрерывностью ИТ-сервиса, который предоставляет Процессу Управления Доступностью информацию о наиболее важных бизнес-процессах. На практике бывает так, что многие меры по улучшению доступности сервиса приводят к улучшению непрерывности ИТ-сервиса и наоборот.
Управление Проблемами
Процесс Управления Проблемами непосредственно участвует в обнаружении причин существующих и потенциальных проблем в сфере доступности сервиса и в их устранении.
Управление Инцидентами
Процесс Управления Инцидентами определяет способ разрешения инцидентов. Этот процесс предоставляет отчеты, содержащие информацию о затратах времени на разрешение инцидентов, ремонт и т. д. Соответствующая информация используется для определения достигнутого Уровня Доступности.
Управление Безопасностью
Процесс Управления Доступностью тесно связан с Процессом Управления Безопасностью, в котором основными вопросами являются:
Конфиденциальность;
Целостность;
Доступность.
Критерии безопасности следует учитывать при определении требований к доступности. Процесс Управления Доступностью может дать ценную информацию Процессу Управления Безопасностью, особенно о новых услугах.
Управление Изменениями
Процесс Управления Доступностью информирует Процесс Управления Изменениями о вопросах обслуживания новых услуг и их элементов и инициирует проведение изменений, обусловленных вопросами доступности. Процесс Управления Изменениями информирует Процесс Управления Доступностью о содержании Перспективного Плана Изменений (FSC).
14.3. Процесс
Для соответствия стандартам высокой доступности сервиса производится дублирование важных компонентов там, где это возможно, и используются системы обнаружения и устранения сбоев. Часто в случае обнаружения дефекта начинают автоматически действовать резервные системы. Тем не менее, в таких ситуациях также необходимо принимать организационные меры, и их может обеспечить Процесс Управления Доступностью.

Рис. 14.2. Входы и выходы Процесса Управления Доступностью (источник: OGC)
Процесс Управления Доступностью начинает действовать после того, как бизнес четко определил свои требования к доступности сервиса. Это непрерывный процесс, который заканчивается только тогда, когда прекращается предоставление сервиса.
Входами для Процесса Управления Доступностью являются (рис. 14.2):
Требования бизнеса к доступности;
Оценка влияния на все бизнес-процессы, поддерживаемые ИТ;
Требования к доступности, надежности и обслуживанию ИТ-компонентов инфраструктуры;
Данные о неисправностях, затрагивающих услуги или их компоненты, обычно в форме записей и отчетов об инцидентах и проблемах;
Данные о конфигурациях услуг и их компонентах и данные мониторинга;
Достигнутые Уровни Сервиса в сравнении с согласованными уровнями для всех услуг, оговоренных в соглашении о предоставлении сервиса.
Выходы :
Критерии разработки архитектуры для обеспечения доступности и восстановления новых и улучшаемых ИТ-услуг;
Технология, обеспечивающая устойчивость инфраструктуры и позволяющая уменьшить или устранить воздействие дефектных компонентов;
Гарантии доступности, надежности и обслуживания компонентов инфраструктуры, необходимые для предоставления ИТ-сервиса;
Отчеты о достигнутых Уровнях Доступности, надежности и обслуживания;
Требования к мониторингу доступности, надежности и обслуживания;
План обеспечения доступности для проведения проактивного улучшения ИТ-инфраструктуры.
14.4. Виды деятельности
В рамках Процесса Управления Доступностью выполняется ряд ключевых видов деятельности, связанных с планированием и мониторингом, а именно:
Планирование
Определение требований к доступности сервиса;
Проектирование систем для достижения требуемого Уровня Доступности;
Проектирование систем для достижения требуемой способности восстановления ;
Вопросы безопасности;
Управление обслуживанием;
Разработка Плана Доступности.
Мониторинг
Проведение измерений и составление отчетов.
Ниже дается описание основных видов деятельности.
14.4.1. Определение требований к доступности сервиса
Данный вид работ должен выполняться до заключения соглашения об Уровне Сервиса, и он затрагивает новые ИТ-услуги и изменения в уже существующих услугах. ИТ-организация должна определить как можно быстрее, будет ли она выполнять эти требования и если да, то как. Во время выполнения этого вида деятельности определяются:
Ключевые бизнес-функции;
Согласованный период простоя ИТ-сервиса;
Количественная оценка требований к доступности сервиса;
Количественная оценка воздействия незапланированного простоя на бизнес-функции;
Рабочие часы заказчика;
Соглашения об «окнах» для планового обслуживания.
Четкое определение требований к доступности сервиса на ранних этапах позволяет избежать недоразумений и неправильного толкования договоренностей на более поздних этапах. Требования заказчика необходимо сопоставлять с теми, которые организация может предоставить. Если выявляется несоответствие, то следует определить влияние такого несоответствия на стоимость услуг.
14.4.2. Проектирование систем для достижения требуемого Уровня Доступности
Следует как можно раньше выявить различные виды уязвимости, влияющие на доступность. Это позволит избежать неоправданно высокой стоимости разработки, незапланированных расходов на более поздних этапах, наличия Единой точки сбоя (SPOF), дополнительных затрат по счетам поставщиков и задержек с выпуском релизов
Хорошее проектирование, выполненное с учетом стандартов доступности, позволит заключить с поставщиками эффективные договоры на обслуживание. При проектировании используется ряд методов, таких как Анализ степени влияния сбоя компонента (CFIA – см. раздел 14.4.9) для выявления отказов, вызванных наличием SPOF, методика CCTA по анализу и Управлению Рисками (CRAMM – см. главу «Управление Непрерывностью ИТ-сервиса») и методы моделирования. Если требования стандартов доступности не могут быть удовлетворены, лучший путь – попытаться внести соответствующие усовершенствования в проект. В обеспечении соответствия стандартам может помочь использование дополнительных технологий, других методов, инструментальных средств разработки, другой стратегии Управления Релизами, улучшение или изменение процесса проектирования.
Если требования особенно высоки, то можно попытаться использовать другую отказоустойчивую технологию, другие Процессы Управления Услугами (Управление Инцидентами, Проблемами и Изменениями) или дополнительные ресурсы Сервис-менеджмента. Выбор варианта во многом зависит от имеющихся финансовых средств.
14.4.3. Проектирование систем для достижения требуемого Уровня Обслуживания
Поскольку постоянная доступность бывает редко достижима, следует учитывать периоды возможной недоступности сервиса. При прерывании сервиса важно быстро и правильно устранить сбой и попытаться достигнуть согласованных стандартов доступности. Проектирование процедур восстановления включает в себя такие аспекты, как использование эффективного Процесса Управления Инцидентами и соответствующие процедуры эскалации, оповещения, резервного копирования и восстановления. Задачи, ответственность и полномочия должны быть четко определены.
14.4.4. Ключевые вопросы безопасности
Безопасность и надежность тесно взаимосвязаны. Недостаточная проработка вопросов информационной безопасности может повлиять на доступность сервиса. Высокий Уровень Доступности должен поддерживаться эффективно действующей системой информационной безопасности. На этапе планирования следует учитывать вопросы безопасности и анализировать их воздействие на предоставление услуг.
Среди вопросов могут быть следующие :
Определение лиц, имеющих право доступа в защищенные области;
14.4.5. Управление Обслуживанием
В обычной практике всегда бывают запланированные периоды недоступности сервиса. Эти периоды можно использовать для проведения превентивных действий, таких как обновление программного и аппаратного обеспечения, а также выполнения изменений. Однако в условиях непрерывного бизнеса становиться все труднее определить периоды, выделяемые для обслуживания. Проектирование, реализация и контроль деятельности по обслуживанию систем стали одним из важных направлений работы Процесса Управления Доступностью.
Обслуживание следует проводить в такие периоды, когда степень его воздействия на предоставление услуг является минимальной. Это значит, что необходимо заранее определить цели обслуживания, период его проведения, и какие работы при этом будут выполняться (для этого можно использовать метод Анализа влияния отказа компонентов – CFIA). Такая информация об обслуживании очень важна для Процесса Управления Изменениями и для других процессов.
14.4.6. Проведение измерений и составление отчетов
Проведение измерений и составление отчетов являются важными видами деятельности в Процессе Управления Доступностью, т. к. они создают основу для верификации соглашений о предоставлении сервиса, для разрешения проблем и выработки предложений по улучшению сервиса.
Если вы не измеряете, вы не можете управлять.
Если вы не измеряете, вы не можете улучшать.
Если вы не измеряете, вам, вероятно, все равно.
Если вы не можете влиять, то не стоит и измерять.
Цикл жизни инцидента включает в себя следующие этапы:
Возникновение инцидента : время, когда пользователь узнал о сбое или когда сбой был обнаружен (автоматически или вручную).
Обнаружение : поставщик сервиса проинформирован о сбое. Инцидент получает статус «Сообщено». Затраченное на это время известно как время обнаружения.
Реагирование : поставщику сервиса необходимо время, чтобы прореагировать на инцидент. Это время реагирования, оно используется для проведения диагностики, за которой следует выполнение ремонтных работ. В Процесс Управления Инцидентами входят такие виды работ, как Прием и Регистрация инцидентов, Классификация, Сопоставление, Анализ и Диагностика.
Ремонт : поставщик сервиса восстанавливает компоненты, которые вызвали сбой.
Восстановление сервиса : сервис восстановлен. При этом выполняются такие работы, как конфигурирование и инициализация, и затем производится восстановление предоставления сервиса пользователям.
На рис. 14.3 показаны периоды времени, которые поддаются измерению.

Рис. 14.3. Измерение доступности (источник: OGC)
Как видно из рисунка, время реагирования ИТ-организации и внешних подрядчиков является одним из факторов, определяющих время простоя. Поскольку этот фактор непосредственно влияет на качество сервиса и ИТ-организация может его контролировать, то в соглашения об Уровне Сервиса можно включать договоренности относительно времени реагирования. При измерениях можно брать средние значения для получения правильного представления о соответствующих параметрах. Средние значения можно использовать для определения достигнутого Уровня Сервиса и для оценки ожидаемой в будущем доступности. Эту информацию можно использовать при разработке Планов Улучшения Сервиса.
В Процессе Управления Доступностью, как правило, используются следующие метрики:
Среднее время ремонта (Mean Time to Repair – MTTR) : среднее время между возникновением сбоя и восстановлением сервиса, также известное как «простой». Оно складывается из времени обнаружения сбоя и времени разрешения сбоя. Данная метрика относится к таким аспектам сервиса, как способность восстановления и обслуживаемость .
Среднее время между сбоями (Mean Time Between Failures – MTBF) : среднее время между восстановлением после одного сбоя и возникновением другого, также известное как «период работоспособного состояния» (uptime). Данная метрика относится к надежности сервиса.
Среднее время между системными инцидентами (Mean Time Between System Incidents – MTBSI) : среднее время между двумя последовательными инцидентами. Данная метрика представляет собой сумму двух метрик MTTR и MTBF.
Соотношение метрик MTBF и MTBSI помогает понять, имело ли место много незначительных сбоев или было несколько серьезных нарушений в работе.
В отчеты о доступности сервиса могут быть включены следующие метрики:
Коэффициент доступности (или недоступности) сервиса, выраженный в метриках MTTR, MTBSI и MTBF;
Общее время работоспособного состояния и время простоя;
Количество сбоев;
Дополнительная информация о сбоях, которые могут привести в настоящее время или в будущем к более высокому Уровню Недоступности Систем, чем было заранее согласовано.
Проблема составления отчетов состоит в том, что представленные выше метрики могут не восприниматься заказчиком. Поэтому отчеты о доступности сервиса должны составляться с точки зрения заказчика. Отчет в первую очередь должен давать информацию о доступности сервиса для наиболее важных бизнес-функций и о доступности данных (т. е. давать бизнес-представления), а не о доступности технических ИТ-компонентов. Отчеты должны быть написаны на понятном заказчику языке.
14.4.7. Разработка Плана Обеспечения Доступности
Одним из основных результатов процесса является План Доступности . Это долгосрочный План Обеспечения Доступности Сервиса на несколько последующих лет, он не является Планом Внедрения Процесса Управления Доступностью.
План – это живой документ. В начале он должен дать описание текущей ситуации, а затем в него можно включать рекомендации и конкретные виды работ по улучшению существующих услуг, а также предложения по вводу новых услуг и их обслуживанию. Для составления полного и точного плана необходимо взаимодействие с такими Процессами, как Управление Уровнем Сервиса, Управление Непрерывностью ИТ-сервиса, Управление Финансами ИТ-сервиса, а также с Управлением Разработкой Приложений (напрямую или через Процесс Управления Изменениями).
14.4.8. Инструментальные средства
Для достижения эффективности Процесс Управления Доступностью должен использовать ряд инструментальных средств следующего назначения:
Определение времени простоя;
Фиксация исторической информации;
Создание отчетов;
Статистический анализ;
Анализ воздействия.
Процесс Управления Доступностью берет информацию из записей Процесса Управления инцидентами, Базы Данных CMDB и из Базы Данных Процесса Управления Мощностями (CL). Эта информация может храниться в специальной Базе Данных Процесса Управления Доступностью.
14.4.9. Методы и методики
В настоящее время существует широкий спектр методов и методик Управления Доступностью, которые помогают в проведении планирования, улучшения доступности и в составлении отчетов. Наиболее важные из них приведены ниже.
Анализ влияния отказа компонентов (CFIA)
Данный метод предполагает использование матрицы доступности стратегических компонентов и их ролей в каждой услуге. При разработке такой матрицы очень полезной может оказаться база данных CMDB.
Пример матрицы CFIA на рис. 14.4 показывает, что Конфигурационные Единицы, которые для многих услуг помечены символом «X», являются важными элементами ИТ-инфраструктуры (анализ по горизонтали) и что услуги, часто отмечаемые символом «X», являются комплексными и подвержены сбоям (анализ по вертикали). Этот метод также можно применять для изучения степени зависимости от сторонних организаций (усовершенствованный метод CFIA).
| Конфигурационная единица | Услуга А | Услуга Б |
| PC № 1 | B | B |
| PC № 2 | B | |
| Кабель № 1 | B | B |
| Кабель № 2 | B | |
| Разъем № 1 | X | X |
| Разъем № 2 | X | |
| Сегмент сети Ethernet | X | X |
| Маршрутизатор | X | X |
| Канал глобальной сети (WAN) | X | X |
| Маршрутизатор | X | X |
| Сегмент | X | X |
| Сетевой информационный центр | A | A |
| Сервер | B | B |
| Системное программное обеспечение | B | B |
| Приложения | B | B |
| База данных | X | X |
X – сбой/дефект означает, что услуга недоступна
А – безотказная конфигурация
В – безотказная конфигурация, с переключением
« » – нет воздействия
Рис. 14.4. Матрица CFIA (